
Beberapa hari yang lalu saya berbicara dengan teman saya melalui WhatsApp hingga pada suatu topik bahwa ada yang membuat sebuah bahasa pemrograman dengan bahasa jaksel , ada juga yang menggunakan Aksara Jawa (hanacaraka). Saya juga ingat dulu, ada orang yang membuat bahasa interpreter BAIK, sintaksnya menggunakan Bahasa Indonesia:
Sebelumnya, saya juga pernah melakukan eksplorasi terkait pembuatan bahasa pemrograman. Dulu saya melihat video untuk membuat bahasa pemrograman compiled, tentu saja prosesnya cukup rumit dan memerlukan pengetahuan yang mendalam, karena syntax harus diterjemahkan ke dalam bahasa assembly atau bahasa mesin.
Kemarin, saya mendapatkan sebuah playlist YouTube tentang membuat bahasa pemrograman sendiri dengan python. Salah satu komentar dalam video tersebut yang menarik adalah "Creating Interpreter using interpreted programming language.".
Hal ini cukup lucu, karena Python sendiri adalah bahasa interpreted, jika kita membuat interpreter dengan python, maka proses yang akan terjadi adalah: bahasa kita -> diterjemahkan ke python -> diterjemahkan ke bahasa komputer. Tentu saja secara performa akan sangat menurun.
Kemudian, saya mencoba untuk membuat interpreter menggunakan GO yang compiled. Anda dapat melihat bahasa pemrograman yang coba saya buat (IndoScript) di repositori berikut ini:
Langkah-Langkah Membuat Bahasa Pemrograman Interpreted
Saya tidak akan membuat tutorial secara lengkap, karena akan menjadi tulisan yang sangat panjang, mungkin bahkan bisa menjadi sebuah buku. Jika anda tertarik untuk mengikuti tutorial silahkan lihat playlist yang sudah saya sebutkan sebelumnya.
Berikut ini adalah langkah-langkah secara umum yang harus dilakukan dalam membuat bahasa pemrograman sendiri:
Mendefinisikan Grammar
Langkah pertama, kita harus mendefinisikan grammar atau bagaimana syntax umum bahasa yang akan kita buat, ini juga akan menentukan urutan operasi mana yang harus didahulukan. Misalnya saja dalam operasi aritmatika kita mengenal penambahan (+), pengurangan (-), pembagian (/), dan perkalian (*). Tentu saja pembagian dan perkalian harus kita utamakan, harus dieksekusi terlebih dahulu sebelum kita mengeksekusi hasilnya dengan operasi yang lebih rendah prioritasnya (penambahan dan pengurangan).
Anda dapat menuliskan grammar ini di mana saja, misalnya membuat file .txt di project anda ataupun dokumentasi tersendiri. Ini akan berguna ketika bahasa yang anda buat semakin berkembang, atau terjadi masalah dalam urutan operasi yang dilakukan. Tidak ada format khusus untuk membuat grammar, anda bisa membuat sesuka hati anda. Contoh grammar menggunakan bahasa Indonesia adalah:
deklarasi : KATKUN:var PENGENAL SD ekspresi TK
: KATKUN:jika BKURUNG ekspresi TKURUNG BKURAWAL deklarasi* TKURAWAL
: KATKUN:fungsi BKURUNG (PENGENAL)?(KOMA PENGENAL)?* TKURUNG BKURAWAL deklarasi* TKURAWAL
: atom-fn TK
: KATKUN:balikan TK
ekspresi : term ((TAMBAH|KURANG) term)*?
term : atom ((KALI|BAGI) atom)*?
atom : BUL|DES|PENGENAL|TEKS
: BKURUNG ekspresi TKURUNG
atom-fn : PENGENAL BKURUNG (ekspresi)?(KOMA ekspresi)?* TKURUNGDalam grammar di atas terdapat kata-kata yang dikenal seperti PENGENAL, BKURUNG (Buka Kurung), TKURUNG (Tutup Kurung), KATKUN (Kata Kunci / Keyword), hal itu nanti akan kita sebut dengan istilah TOKEN.
Dengan contoh grammar di atas, kode berikut akan valid secara sintaks:
fungsi hitung_umur(tahun_lahir, tahun_sekarang){
var umur = tahun_sekarang - tahun_lahir;
balikan umur;
}
var tahun_lahir = 2003;
var tahun_sekarang = 2004;
cetakBr("UMUR SAYA:");
cetak(hitung_umur(tahun_lahir, tahun_sekarang));
Membuat Lexer
Proses lexing atau analisis akan mengubah setiap karakter dalam kode dengan sintaks bahasa yang kita buat menjadi token-token seperti: TK, BKURUNG, TEKS, TKURUNG, dan sebagainya.
Contoh kode untuk pendefinisian token:
package lekser
import "indoscript/utils"
type JenisToken string
const (
T_BUL JenisToken = "BUL"
T_DES JenisToken = "DES"
T_TAMBAH JenisToken = "TAMBAH"
T_KURANG JenisToken = "KURANG"
T_KALI JenisToken = "KALI"
T_BAGI JenisToken = "BAGI"
T_BKURUNG JenisToken = "BKURUNG"
T_TKURUNG JenisToken = "TKURUNG"
T_BKURAWAL JenisToken = "BKURAWAL"
T_TKURAWAL JenisToken = "TKURAWAL"
T_KATKUN JenisToken = "KATKUN"
T_PENGENAL JenisToken = "PENGENAL"
T_TK JenisToken = "TK"
T_KOMA JenisToken = "KOMA"
T_TEKS JenisToken = "TEKS"
T_ADF JenisToken = "ADF"
)
// Struktur Token
type Token struct {
utils.BasisPosisi
Jenis JenisToken
Isi interface{}
}
Selanjutnya, untuk contoh kode Lexer-nya:
package lekser
// Menyimpan teks dan posisi kursor saat ini
type Lekser struct {
teks string
indeks int
baris int
kolom int
karakterSaatIni string
}
// Mulai dari karakter indeks 0
func LekserBaru(teks string) Lekser {
lek := Lekser{
teks: teks,
indeks: -1,
baris: 1,
kolom: -1,
karakterSaatIni: "",
}
lek.maju()
return lek
}
// Pendefinisian karakter
var ANGKA = []string{"0", "1", "2", "3", "4", "5", "6", "7", "8", "9"}
var HURUF = []string{
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z",
}
var HURUF_ANGKA = append(ANGKA, HURUF...)
var PENGENAL_VALID = append(HURUF_ANGKA, []string{"_"}...)
Dalam kode di atas kita juga melihat pendefinisian bagaimana identifier (pengenal) yang valid, yang dapat digunakan untuk nama fungsi dan variabel.
Selanjutnya, untuk contoh kode utamanya, yaitu mengubah teks menjadi token:
package lekser
import "slices"
func (lek *Lekser) Tokenisasi() ([]Token, *KesalahanLekser) {
var tokenToken []Token = make([]Token, 0)
for lek.karakterSaatIni != "" {
// Jika karakter saat ini angka ataupun huruf (bukan simbol)
// Memerlukan penanganan khusus
if slices.Contains(ANGKA, lek.karakterSaatIni) {
tokenToken = append(tokenToken, lek.tokenisasiAngka())
continue
} else if slices.Contains(HURUF, lek.karakterSaatIni) {
tokenToken = append(tokenToken, lek.tokenisasiKataKunci())
continue
} else {
switch lek.karakterSaatIni {
case "\t", " ", "\n":
// Jika karakter petik, kemungkinan besar berupa teks/string
case "'", "\"":
tokenToken = append(tokenToken, lek.tokenisasiTeks())
continue
// Case selanjutnya, simbol-simbol
case "+":
tokenToken = append(tokenToken, Token{
Jenis: T_TAMBAH,
BasisPosisi: lek.basisPosisi(),
})
case "-":
tokenToken = append(tokenToken, Token{
Jenis: T_KURANG,
BasisPosisi: lek.basisPosisi(),
})
case "*":
tokenToken = append(tokenToken, Token{
Jenis: T_KALI,
BasisPosisi: lek.basisPosisi(),
})
case "/":
tokenToken = append(tokenToken, Token{
Jenis: T_BAGI,
BasisPosisi: lek.basisPosisi(),
})
case "^":
tokenToken = append(tokenToken, Token{
Jenis: T_PANGKAT,
BasisPosisi: lek.basisPosisi(),
})
case "(":
tokenToken = append(tokenToken, Token{
Jenis: T_BKURUNG,
BasisPosisi: lek.basisPosisi(),
})
case ")":
tokenToken = append(tokenToken, Token{
Jenis: T_TKURUNG,
BasisPosisi: lek.basisPosisi(),
})
case ";":
tokenToken = append(tokenToken, Token{
BasisPosisi: lek.basisPosisi(),
Jenis: T_TK,
})
case ",":
tokenToken = append(tokenToken, Token{
BasisPosisi: lek.basisPosisi(),
Jenis: T_KOMA,
})
case "{":
tokenToken = append(tokenToken, Token{
BasisPosisi: lek.basisPosisi(),
Jenis: T_BKURAWAL,
})
case "}":
tokenToken = append(tokenToken, Token{
BasisPosisi: lek.basisPosisi(),
Jenis: T_TKURAWAL,
})
default:
return nil, &KesalahanLekser{
BasisPosisi: lek.basisPosisi(),
detail: "Karakter tidak valid: \"" + lek.karakterSaatIni + "\"",
}
}
}
lek.maju()
}
tokenToken = append(tokenToken, Token{
Jenis: T_ADF,
BasisPosisi: lek.basisPosisi(),
})
return tokenToken, nil
}
// Disini kita bisa proses karakter yang diawali petik tadi
func (lek *Lekser) tokenisasiTeks() Token {
teks := ""
pemisah := lek.karakterSaatIni
posisi := lek.basisPosisi()
// Melakukan looping untuk mengambil karakter didalam tanda petik
// serta menangani escape (Cth: 'Ma\'af')
lek.maju()
escaped := false
for lek.karakterSaatIni != pemisah {
teks = teks + lek.karakterSaatIni
lek.maju()
if lek.karakterSaatIni == "\\" {
escaped = true
lek.maju()
continue
}
if lek.karakterSaatIni == pemisah && !escaped {
break
}
if escaped {
escaped = false
}
}
lek.maju()
return Token{
BasisPosisi: posisi,
Jenis: T_TEKS,
Isi: teks,
}
}
Tentu saja tidak semua kode saya tampilkan, jika anda ingin lebih lengkap, silahkan lihat di tautan repositori saya sebelumnya.
Ketika lexer yang anda buat berhasil melakukan tugasnya maka teks yang berisikan kode dengan syntax bahasa pemrograman kita akan diubah menjadi daftar token, Contohnya dalam kode berikut:
var nama_saya = "Hasan";Akan berubah menjadi list token:
[
Token(Jenis: T_KATKUN, Isi: "var"),
Token(Jenis: T_PENGENAL, Isi: "nama_saya"),
Token(Jenis: T_SD, Isi: null),
Token(Jenis: T_TEKS, Isi: "Hasan"),
Token(Jenis: T_TK, Isi: null),
]Dalam proses tokenisasi biasanya spasi, tab, dan baris baru akan diabaikan (tergantung sintaks bahasa pemrograman yang anda inginkan).
Membuat Parser
Setelah berhasil mengubah teks biasa menjadi daftar token, langkah selanjutnya adalah melakukan parsing. Mengubah token-token menjadi node-node bersarang yang urutannya akan berpengaruh saat eksekusi.
Node sendiri tergantung kebutuhan kita, contohnya kita bisa membuat NodeBilangan, NodeAturVariabel, NodeAmbilVariabel, dan lain-lain.
Contoh pendefinisian struktur node:
type NodeTeks struct {
utils.BasisPosisi
Teks string
}
// Operasi seperti +, -, *, dan /
type NodeOperasi struct {
utils.BasisPosisi
NodeKiri interface{}
Operasi lekser.JenisToken
NodeKanan interface{}
}
type NodeAturVariabel struct {
utils.BasisPosisi
NamaVariabel string
Node interface{}
}
// Node-node lainSelanjutnya, membuat parser:
package pengurai
import (
"indoscript/lekser"
"indoscript/utils"
)
// Menyimpan posisi cursor token saat ini
type Pengurai struct {
daftarToken []lekser.Token
tokenSaatIni *lekser.Token
indeks int
}
func PenguraiBaru(daftarToken []lekser.Token) Pengurai {
pengurai := Pengurai{
daftarToken: daftarToken,
tokenSaatIni: nil,
indeks: -1,
}
pengurai.maju()
return pengurai
}
func (p *Pengurai) Urai() (*NodeAkar, *TokenTakTerduga) {
nodeNode := make([]interface{}, 0)
for p.tokenSaatIni != nil {
if p.tokenSaatIni.Jenis == lekser.T_ADF {
break
}
node, err := p.deklarasi()
if err != nil {
return nil, err
}
nodeNode = append(nodeNode, node)
}
return &NodeAkar{
BasisPosisi: utils.BasisPosisi{
Baris: 0,
Kolom: 0,
},
NodeNode: nodeNode,
}, nil
}
// Melakukan parsing pada grammar jenis deklarasi
func (p *Pengurai) deklarasi() (interface{}, *TokenTakTerduga) {
tok := p.tokenSaatIni
if p.tokenSaatIni.Jenis == lekser.T_KATKUN {
switch tok.Isi {
case lekser.KK_VAR:
return p.deklarasiVar()
case lekser.KK_JIKA:
return p.deklarasiJika()
case lekser.KK_FUNGSI:
return p.deklarasiFungsi()
case lekser.KK_BALIKAN:
return p.deklarasiBalikan()
}
}
if tok.Jenis == lekser.T_PENGENAL {
hasil, err := p.expr()
if err != nil {
return nil, err
}
err = p.tkMaju()
if err != nil {
return nil, err
}
return hasil, nil
}
return nil, &TokenTakTerduga{
BasisPosisi: p.basisPosisi(),
diharapkan: []lekser.JenisToken{lekser.T_KATKUN},
ditemukan: p.tokenSaatIni.Jenis,
}
}
// Melakukan proses parsing deklarasi yang diawali kata kunci "var"
func (p *Pengurai) deklarasiVar() (interface{}, *TokenTakTerduga) {
posisi := p.basisPosisi()
p.maju()
if p.tokenSaatIni.Jenis != lekser.T_PENGENAL {
return nil, &TokenTakTerduga{
BasisPosisi: p.basisPosisi(),
diharapkan: []lekser.JenisToken{lekser.T_PENGENAL},
ditemukan: p.tokenSaatIni.Jenis,
}
}
namaVariabel := p.tokenSaatIni.Isi
p.maju()
if p.tokenSaatIni.Jenis != lekser.T_SD {
return nil, &TokenTakTerduga{
BasisPosisi: p.basisPosisi(),
diharapkan: []lekser.JenisToken{lekser.T_SD},
ditemukan: p.tokenSaatIni.Jenis,
}
}
p.maju()
expr, err := p.expr()
if err != nil {
return nil, err
}
err = p.tkMaju()
if err != nil {
return nil, err
}
return &NodeAturVariabel{
BasisPosisi: posisi,
NamaVariabel: namaVariabel.(string),
Node: expr,
}, nil
}
// Kode lainKetika parser kita berhasil menjalankan tugasnya, token-token berikut:
// Kode Asli:
var umur = 2024 - 2003;
// Token:
[
Token(Jenis: T_KATKUN, Isi: "var"),
Token(Jenis: T_PENGENAL, Isi: "umur"),
Token(Jenis: T_SD, Isi: null),
Token(Jenis: T_BUL, Isi: 2024),
Token(Jenis: T_KURANG, Isi: null),
Token(Jenis: T_BUL, Isi: 2003),
Token(Jenis: T_TK, Isi: null),
]Akan berubah menjadi node bersarang:
[
NodeAturVariabel(
NamaVariabel: "umur",
Node: NodeOperasi(
NodeKiri: NodeBilangan(
Angka: 2024,
),
Operasi: "-",
NodeKanan: NodeBilangan(
Angka: 2003,
),
),
),
]Kita lihat, pada contoh node di atas, NodeOperasi ada di dalam NodeAturVariabel. Maka, NodeOperasi akan kita jalankan terlebih dahulu nantinya.
Membuat Interpreter
Langkah terakhir, setelah kita berhasil mendapatkan Node-Node, kita harus mengeksekusi node tersebut satu per satu, dari atas ke bawah. Berbeda jika kita ingin membuat compiler, kita harus menerjemahkan node tersebut menjadi bahasa mesin (ataupun bahasa perantara yang bisa di-compile ke executable binary).
Langkah pertama dalam interpreter bahasa IndoScript yang saya buat adalah membuat struktur untuk tipe data, karena tentunya tipe TEKS tidak bisa kita operasikan dengan tipe BILANGAN:
package jenis
import (
"errors"
"fmt"
"indoscript/lekser"
"math"
)
type Bilangan struct {
Angka float64
}
func (b *Bilangan) Operasi(targetBil *Bilangan, op lekser.JenisToken) (*Bilangan, error) {
var hasil float64
switch op {
case lekser.T_TAMBAH:
hasil = b.Angka + targetBil.Angka
case lekser.T_KURANG:
hasil = b.Angka - targetBil.Angka
case lekser.T_KALI:
hasil = b.Angka * targetBil.Angka
case lekser.T_BAGI:
hasil = b.Angka / targetBil.Angka
case lekser.T_PANGKAT:
hasil = math.Pow(b.Angka, targetBil.Angka)
default:
return nil, errors.New(fmt.Sprint("Operasi tak terduga: ", op))
}
return &Bilangan{
Angka: hasil,
}, nil
}
Selanjutnya, kita perlu membuat symbol table untuk menyimpan variabel dan fungsi yang sudah kita parsing:
package penerjemah
import (
"errors"
"indoscript/pengurai"
)
type ButirFungsi struct {
namaArgument []string
nodeAkar *pengurai.NodeAkar
}
type TabelSimbol struct {
variabel map[string]interface{}
fungsi map[string]ButirFungsi
induk *TabelSimbol
}
func TabelSimbolBaru(induk *TabelSimbol) TabelSimbol {
ts := TabelSimbol{}
ts.variabel = make(map[string]interface{})
ts.fungsi = make(map[string]ButirFungsi)
ts.induk = induk
return ts
}
func (ts *TabelSimbol) ambilVar(pengenal string) (interface{}, error) {
val, ok := ts.variabel[pengenal]
if !ok && ts.induk != nil {
val, err := ts.induk.ambilVar(pengenal)
if err != nil {
return nil, err
}
return val, nil
} else if !ok {
return nil, errors.New("Variabel tak terdefinisikan : " + pengenal)
}
return val, nil
}
func (ts *TabelSimbol) aturVar(pengenal string, isi interface{}) {
ts.variabel[pengenal] = isi
}
func (ts *TabelSimbol) ambilFung(pengenal string) (*ButirFungsi, error) {
val, ok := ts.fungsi[pengenal]
if !ok && ts.induk != nil {
val, err := ts.induk.ambilFung(pengenal)
if err != nil {
return nil, err
}
return val, nil
} else if !ok {
return nil, errors.New("Fungsi tak terdefinisikan: " + pengenal)
}
return &val, nil
}
func (ts *TabelSimbol) aturFung(pengenal string, namaAgumen []string, nodeAkar *pengurai.NodeAkar) {
ts.fungsi[pengenal] = ButirFungsi{
namaArgument: namaAgumen,
nodeAkar: nodeAkar,
}
}
Dalam tabel simbol yang saya buat, terdapat induk, berguna jika kita memerlukan scoping variabel dan fungsi.
Untuk contoh kode core interpreter-nya sendiri adalah:
package penerjemah
import (
"indoscript/penerjemah/jenis"
"indoscript/pengurai"
"reflect"
)
// Kita memerlukan symbol table
type Penerjemah struct {
ts *TabelSimbol
}
func PenerjemahBaru() Penerjemah {
p := Penerjemah{}
ts := TabelSimbolBaru(nil)
p.ts = &ts
return p
}
// Jika kita memparsing fungsi, tentunya scope variabel akan berubah
// Kita membuat interpreter baru
func (p *Penerjemah) buatAnak() Penerjemah {
ts := TabelSimbolBaru(p.ts)
pb := Penerjemah{
ts: &ts,
}
return pb
}
func (p *Penerjemah) Jalankan(node *pengurai.NodeAkar) *KesalahanPenerjemah {
_, err := p.panggilNode(node)
return err
}
// Mengeksekusi node satu per satu
func (p *Penerjemah) panggilNode(node interface{}) (interface{}, *KesalahanPenerjemah) {
switch v := node.(type) {
case *pengurai.NodeAkar:
return p.nodeAkar(v)
case *pengurai.NodeBilangan:
return p.nodeBilangan(v)
case *pengurai.NodeTeks:
return p.nodeTeks(v)
case *pengurai.NodeBoolean:
return p.nodeBoolean(v)
case *pengurai.NodeOperasi:
return p.nodeOperasi(v)
case *pengurai.NodeOperasiUner:
return p.nodeOperasiUner(v)
case *pengurai.NodeOperasiDanAtau:
return p.nodeOperasiDanAtau(v)
case *pengurai.NodeAturVariabel:
return p.nodeAturVariabel(v)
case *pengurai.NodeAksesVariabel:
return p.nodeAksesVariabel(v)
case *pengurai.NodeAturFungsi:
return p.nodeAturFungsi(v)
case *pengurai.NodePanggilFungsi:
return p.nodePanggilFungsi(v)
case *pengurai.NodeJika:
return p.NodeJika(v)
case *pengurai.NodeBalikan:
return p.nodeBalikan(v)
default:
jenisNode := reflect.TypeOf(v)
return nil, &KesalahanPenerjemah{
pesan: "Node \"" + jenisNode.String() + "\" tak dikenali!",
}
}
}Di sini, setiap node akan diterjemahkan ke dalam sebuah fungsi/method. Contoh kode untuk fungsi nodeOperasi adalah:
package penerjemah
import (
"fmt"
"indoscript/lekser"
"indoscript/penerjemah/jenis"
"indoscript/pengurai"
"reflect"
"slices"
)
func (p *Penerjemah) nodeOperasi(node *pengurai.NodeOperasi) (interface{}, *KesalahanPenerjemah) {
nodeKiri, err := p.panggilNode(node.NodeKiri)
if err != nil {
return nil, err
}
switch kiri := nodeKiri.(type) {
case *jenis.Bilangan:
kanan, err := p.panggilNodeBilangan(node.NodeKanan)
if err != nil {
return nil, err
}
// Kita perlu menghandle operasi boolean (>, <, >=, <=, ==)
if slices.Contains(lekser.TOKEN_PERBANDINGAN, node.Operasi) {
res, er := kiri.OperasiBoolean(kanan, node.Operasi)
if er != nil {
return nil, &KesalahanPenerjemah{
BasisPosisi: node.BasisPosisi,
pesan: er.Error(),
}
}
return res, nil
} else {
bil, er := kiri.Operasi(kanan, node.Operasi)
if er != nil {
return nil, &KesalahanPenerjemah{
BasisPosisi: node.BasisPosisi,
pesan: er.Error(),
}
}
return bil, nil
}
// Operasi tipe data lain
}
return nil, &KesalahanPenerjemah{
BasisPosisi: node.BasisPosisi,
pesan: fmt.Sprint("Operasi tidak dapat dilakukan pada jenis ", reflect.TypeOf(nodeKiri), "!"),
}
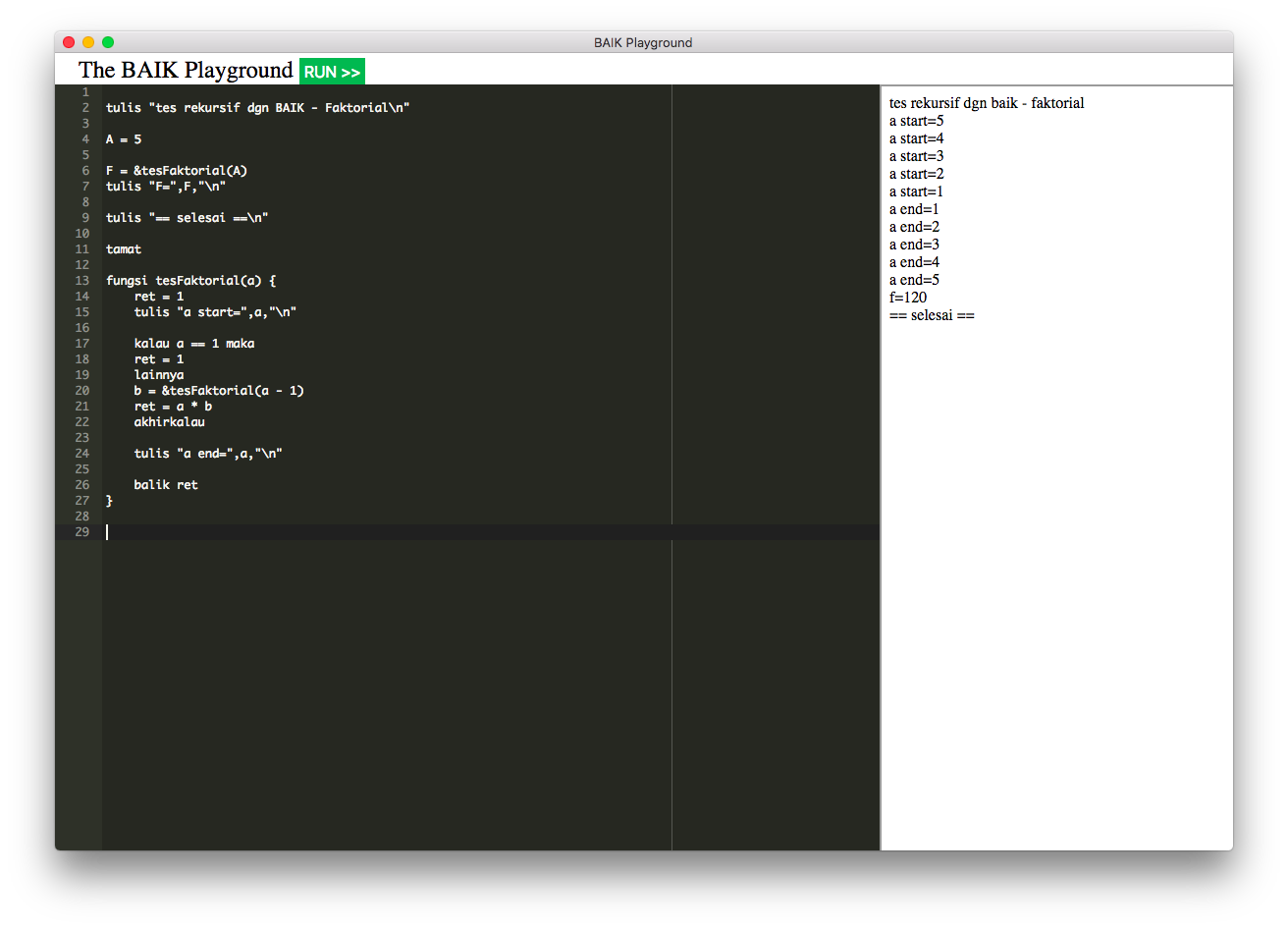
}Interpreter dikatakan benar jika berhasil menerjemahkan node-node yang ada kedalam eksekusi program.
Kesimpulan
Membuat bahasa pemrograman sendiri ternyata tidak sesusah yang dibayangkan, tentunya jika anda menguasai sebuah bahasa pemrograman yang dapat dijadikan alat untuk pembuat interpreter atau compiler.
Tetapi untuk membuat bahasa pemrograman yang "benar", "efektif" dan "efisien" memerlukan orang yang lebih ahli.
Jangan lupa untuk coba melihat bahasa pemrograman dengan sintaks Bahasa Indonesia yang saya buat sendiri:
Semoga Bermanfaat!





